

Microsoft załatał 39 dziur
12 grudnia 2018, 10:49Wraz z grudniowym wydaniem Patch Tuesday Microsoft załatał 9 krytycznych dziur w swoich produktach. jedną z nich jest luka typu zer-day występująca w starczych wersjach Windows.
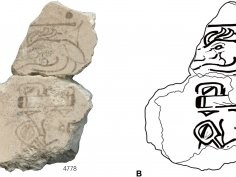
Najstarszy przykład kalendarza Majów znaleziony w fundamentach słynnej piramidy
20 maja 2022, 11:11Ponad 2000 lat temu w dzisiejszym San Bartolo w Gwatemali Majowie rozpoczęli budowę piramidy i siedmiu towarzyszących jej struktur. Kompleks „Las Pinturas” słynny jest ze wspaniałych malunków z późnego okresu preklasycznego, na których widać wpływy kultury Olmeków oraz wczesne pismo Majów. Teraz znaleziono coś jeszcze – fragment muralu z najwcześniejszym znanym nam użyciem kalendarza Majów.

Już w XV wieku chińscy chirurdzy stosowali środki znieczulające
26 maja 2026, 10:55Niezwykłe odkrycie archeologów z Chin rzuca nowe światło na medycynę dynastii Ming i sugeruje, że tamtejsi chirurdzy dysponowali zaskakująco skutecznymi środkami przeciwbólowymi już w XV wieku. Opublikowane właśnie na łamach Antiquity wyniki badań łączących archeologię, chemię analityczną i historię medycyny, każą nam przemyśleć na nowo to, co wiemy o dawnej chirurgii.
Pojawiam się i znikam
8 lipca 2009, 12:06Jak uzyskać współczesną wersję atramentu sympatycznego? Wystarczy wykorzystać nanocząsteczki złota, pokryte specjalną substancją o włosowatej budowie. Potem włączamy światło ultrafioletowe i po zaprogramowanym czasie tekst czy obraz znika.
Superglue do rogówki
28 sierpnia 2012, 11:42Klej do mocowania płatka rogówki poprawi w przyszłości bezpieczeństwo refrakcyjnych operacji laserowych oczu.
Ołów pozwoli odczytać starożytne teksty?
23 marca 2016, 10:07Zwoje z Herkulanum zostały pogrzebane pod wulkanicznymi popiołami pochodzącymi z eksplozji Wezuwiusza w 79 roku. Spalone papirusy mogą skrywać nieznane ludzkości starożytne teksty. Dotychczas jednak części z nich nie udało się odczytać, a wcześniejsze próby rozwijania papirusów kończyły się ich zniszczeniem. Od niedawna jest jednak nadzieja, że w niedalekiej przyszłości poznamy, jakie tajemnice kryją

Po zakończeniu ciąży kobiety często czują fantomowe kopnięcia dziecka
28 listopada 2019, 17:21Wiele kobiet ma po porodzie wrażenia przypominające kopnięcia dziecka. Fantomowe kopnięcia mogą występować latami od zakończenia ciąży. U rekordzistki z australijskiego badania utrzymywały się one od ok. 28 lat.
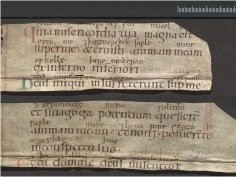
Odkryto kolejne kawałki Psałterza N. Mógł należeć do siostry ostatniego anglosaskiego króla Anglii
12 stycznia 2024, 12:25W Archiwum Regionalnym w Alkmaar w Holandii odkryto 21 fragmentów XI-wiecznego psałterza, który został pocięty i użyty około XVII wieku do usztywnienia opraw książek. To już kolejne kawałki tak zwanego Psałterza N, którego fragmenty znajdowane są od lat 60. XX wieku. Odkryto je między innymi w Elblągu. Niezwykłe dzieło, spisane po łacinie ze staroangielskimi glosami, mogło należeć do anglosaskiej księżniczki, która uciekła z Anglii po normandzkim podboju.
Staruszek długopis
26 listopada 2006, 11:09W każdej sekundzie na świecie sprzedaje się 57 długopisów. Potem, pożyczane przez rodzinę, kolegów i koleżanki, przechodzą z rąk do rąk i rzadko kiedy wracają do prawowitego właściciela. Wynaleziono je, ponieważ kogoś bardzo frustrowało używanie robiącego kłopotliwe kleksy pióra.
Okulary do zapisywania życia
9 czerwca 2010, 10:59Sony Computer Science Laboratories pracują nad okularami, które będą rejestrowały różne wydarzenia z punktu widzenia ich posiadacza. Urządzenie śledzi ruchy oczu i zapisuje to, na czym się skupiamy. Składa się ono z okularów, aparatu cyfrowego i działających na podczerwień diod LED.

